Interview with a Data Scientist: What is Machine Learning?
At Cynnovative, machine learning is a core component of our technical work. We don’t often discuss what machine learning is amongst ourselves because it is already completely integrated into our multidisciplinary solutions. However, we realized there are many people who want to know more about it from the perspective of those of us who work with machine learning every day.
We (virtually) sat down with Data Scientist Matt S. to get his take on machine learning.
Question: How would you define machine learning?
Answer: If you’ve spent a bit of time browsing blogs and medium posts that attempt to give introductions to data science or machine learning, you’ve probably seen a certain diagram. It’s three concentric circles with the outermost labeled “Artificial Intelligence,” then “Machine Learning”, and finally “Deep Learning.” The machine learning circle likely includes a definition along the lines of “a program that learns to improve without explicit instruction to do so”1 or “algorithms that improve as they’re given more data.”
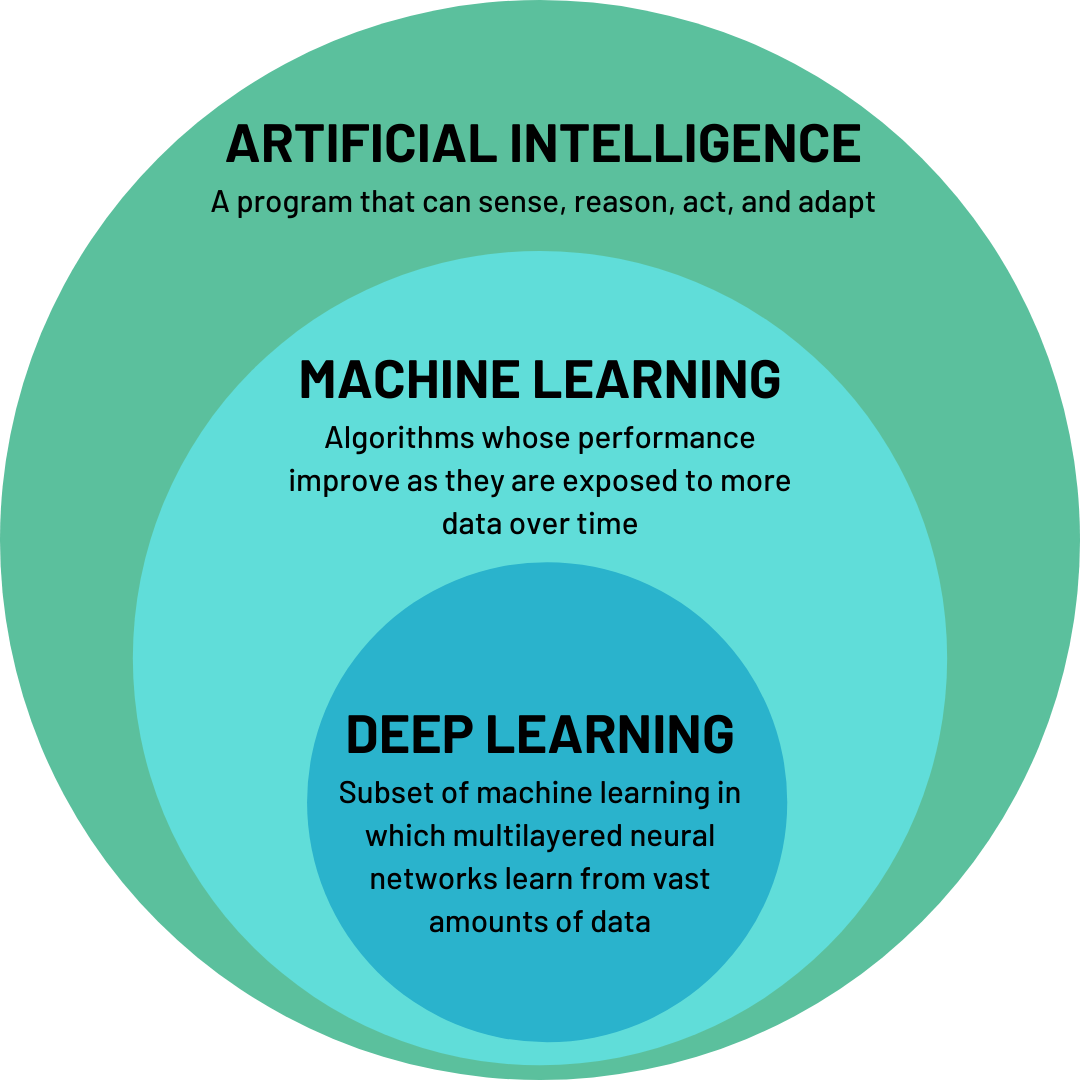
Example of concentric circle diagram
These definitions aren’t just vague; I’d argue they’re wrong. A machine learning algorithm is given explicit instructions on how to improve, they’re just mathematical and a bit abstract. And more data does not always make a model better.2
A definition that I agree with defines a machine learning model as a composite of three core elements: the estimator, the loss function, and the optimizer. The estimator is the part that maps your data from the input to output. Sometimes it’s also referred to as the “model,” but I think this creates confusion, since it’s common to refer to all three elements together as the model. In a supervised learning context, the estimator maps features to labels. For unsupervised clustering, it would also apply cluster labels. In NLP representation learning, it would transform a word or sentence to a 128-D vector that can then be fed into another model. When doing reinforcement learning, the estimator is the component that will pick the (hopefully) next optimal action given a state. This component is the most visible and what most people think of when they think of machine learning, but it’s not everything.
What about the other two components?
The learning part of machine learning lives in those two.
As a machine learning model trains, it needs a concept of wrongness–how far off it is from where it wants to be. The loss is the mathematical representation of this. Loss can be simple, like Mean Squared Error (MSE), or it can be an entirely custom metric that the machine learning engineer has decided is appropriate for the problem they are solving. The choice of error is not an arbitrary decision and is just as important as the choice in model architecture. Lastly, the optimizer is the part that adjusts the model. When training a deep learning model for classification, the optimizer sets the rules for how the weights and biases will be adjusted when comparing predictions to true labels, for example. It can impact the speed with which a model converges to its optimum, and even whether it finds its global optimum at all.
I’ll stop there, since that’s a lot to digest, but I just want to add that this was only a discussion of a machine learning model. Machine learning as a field encompasses lots of other work with data that goes into operationalizing the model, like smart and efficient feature engineering, transforming data, hyperparameter tuning, and more. We could talk all day about it.
Why should people who aren’t in this field care about it?
Computing in general is great because it allows us to automate tasks that are either too boring for people to do or would require too much manpower to be feasible. So one reason machine learning is so useful is that it can be used on very large amounts of data.
For example, each of us gets specific recommendations of what to watch next on Netflix. Obviously, it’s infeasible for Netflix to hire people to create individualized recommendations for every user manually. Machine learning makes those recommendations possible.
There are also tasks that aren’t about scale but just about how humans work – we can’t keep a giant spreadsheet in our head and do all of the calculations, but a machine learning algorithm can.
What’s a high-level example of standard programming versus machine learning?
Again, I think there’s some diagram floating around the internet for this, but I think this one is a bit more accurate. It represents traditional programming as “rules + data = answers” and machine learning as “data + answers = rules.” Now, this isn’t always the case. With unsupervised learning, for example, you don’t have the “answers,” you’re creating a model that should extract meaningful groups or representations that you’re not necessarily aware of. But on a high level I think this contrast is fairly useful. With a standard program, the exact results (assuming no bugs, which is obviously a very big assumption) are known when the program is written. If you write an alarm clock app, you know that if you set the alarm to 6 AM, whatever sound you’ve selected will, in fact, go off at that time. But a machine learning model is meant to extract information from the data that we’re not necessarily aware of. If you’re making a model to segment groups of users, you don’t know ahead of time which users belong in which groups. If you did, you wouldn’t need a machine learning model at all! I guess another way of putting it would be that a standard program just doesn’t require a training phase.
I should note though that I’m also not a software engineer, so it’s hard for me to compare machine learning to a field I’m not as familiar with. Maybe that could be a future blog post.
Why do you do this type of work?
Everyone at Cynnovative does this work because we are naturally very curious people. What drew me to Cynnovative is the constant desire to learn. We want the company to be competitive and successful, but we also want our work to be exciting and creative. The company culture is incredibly supportive of intellectual growth, and there’s so much research on machine learning and data science that you can always find a new topic to dive into.
Citations:
1: Arthur Samuel 1959
2: https://www.semanticscholar.org/paper/Poisoning-Attacks-against-Support-Vector-Machines-Biggio-Nelson/990a02f20529f5ce3b382f1d54648afaab391179